
Running High Scale Low Latency Database with Zero Data In Memory?
I was talking to one of my oldest database colleagues (and a very dear friend of mine). We were chatting about how key/value stores and databases are evolving. My friend mentioned how they always seem to be revolving around in-memory solutions and cache. The main rant was how this kind of thing doesn’t scale well, while being expensive and complicated to maintain.
My friend’s background story was that they are running an application that uses a user profile with almost 700 million profiles (their total size was around 2TB, with a replication factor of 2). Since the access to the user profile is very random. In short terms, it means, the application is not able to “guess” which user it would need next as that is pretty much random. Therefore, they could not use pre-heating of the data to memory. Their main issue was that every now and then they were getting high peaks of over 500k operations per second of this kind of mixed workloads and that didn’t scale very well.
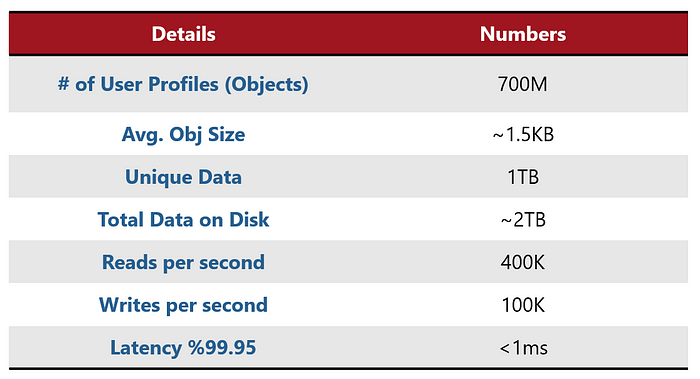
User Profile use case summary
Oracle Week 2017: Docker Concepts for Oracle/MySQL DBAs and DevOps (slides)
Oracle Week in Israel is a reason for celebration. Every year (and for the past 24 years), between a 1500 and 2000 Oracle professional are gathered for a 5 days conference on Oracle related educational topics. Each day is a full-day seminar on a specific topic – 9am to 4:30pm talking about something related to Oracle technologies. This year, I had 4 full-day back-to-back seminars – which is way more than the average speaker. Some of the sessions were on topics I spoke on last year and the year before (SQL and PL/SQL), but some were completely new.
This seminar was about Docker Containers: introduction and how to use them combined with Oracle RDBMs and MySQL.
Before the conference, I wasn’t totally sure if it’s going to open. The minimum requirement to open a session is around 10-12 people and the organizer warned me that the chances are slim – but I was sure this is a “hot” topic and submitted this topic anyway. I was surprised to see that over 30 people registered to the session – and stayed just until the end. The feedbacks were also great (4.95 out of 5) so thank you guys! 🙂
Docker Containers
Docker is an open source software development platform. Its main benefit is to package applications in container, a lightweight, stand-alone, executable package of a piece of software that includes everything needed to run it: code, runtime, system tools, system libraries, settings. The container isolates the software from its surroundings, for example differences between development and staging environments, and helps reduce conflicts between teams running different software on the same infrastructure. That means that we can create and maintain a simple deployable “boxes” of “application” (or micro-services) – including code and databases.
One of the cool things you can do with it is to deploy a full-scale Oracle RDBMS (or MySQL or other NoSQL solutions) in a matter of minutes. No need to install OS, pre-requirements or even create an instance – it’s all self contained in the container itself.
In this session we learned how to use Docker, how to use it with databases and why it might be a good idea to combine them. We even had an open discussion about ideas how to implement this in different environment.
This is the Agenda for the session:
Docker overview – why do we even need containers?
Installing Docker and getting started
Images and Containers
Docker Networks
Docker Storage and Volumes
Oracle and Docker
Docker tools, GUI and Swarm
Closing Dataguard Transfer and Apply Gaps
In the last week, I had two customers that had some failures with their standby databases and contacted me about closing their DG gaps. Since this kind of problems is common, and since the solutions are fairly easy I thought it worth a post to document this for their and your use.
Before we begin, let’s understand what dataguard gaps are. There are two types of gaps: transport and apply gaps. The transport gaps problem usually starts after a network disconnection between the primary and standby databases. At this time, the archive logs are not being shipped between the databases – and this is called a transport gap. The other case is the apply gap: in this case, we have all the files but the standby didn’t finish applying them all yet.
Our problem begins when during a transport gap, the archives we need to close the gap (in the primary) are removed. In this case the dataguard will not be able to continue rolling the log files and will hang. This is exactly what happen to my customers, and their question was what to do next – preferably, without rebuilding the entire standby database.
Error ORA-14766: Unable To Obtain A Stable Metadata Snapshot
A customer called me up and said that he’s hitting “ORA-14766: Unable To Obtain A Stable Metadata Snapshot” and he’s coming up dry on his google search.
This was the first time I encountered this problem, so I thought I’d investigate and write a few words about it, because the problem seems it might be pretty common and the solution was a bit weird.

ilOUG meetup: Oracle 12c New Features For Better Performance (slides)
It’s been a while since the Israeli user group (iloug) had a technology meetup (SIG meeting). The last time that happened was over two years ago – and since then, we only had the bigger conferences with guests from all over the world. Yesterday we renewed that long time tradition and held such a meetup.
Although I am not part of the OUG board (and not for the lack of trying, just no elections for a very long time), I volunteered to help host the meeting together with Oracle Ace Associate Oren Nakdimon (@dboriented, http://db-oriented.com). I also presented a new session: “Oracle 12c New Features For Better Performance” (see below for the agenda and slide deck).
The Best Non-Important Feature of 12cR2: History Command
So I’ve been using Oracle 12cR2 for a couple of weeks now (getting ready to ilOUG meetup in a few weeks), and I decided to share my favorite non-important feature of the new version: the History command for SQLPlus.
As most of you already know, I’m a huge fan of SQLcl (aka SQL Developer Command Line Interface). I’ve written about it a little, and talked about it in conferences a lot. In the last conference someone came up and asked me, “Okay, sqlplus can do most of those stuff – but what do you use the most” and I answered that the history command actually changed the way I work.
That was the case until Oracle 12cR2. Starting 12.2.0.1, SQLPlus now has the ability to show list of last commands. Now, this might sound like a small change, but it’s so useful I’m surprised SQLPlus took only 31 years to implement it…